SQL em escala com o Apache Spark SQL e DataFrames - conceitos, arquitetura e exemplos
Combine, agregue, filtre dados em escala usando seu amigável SQL com uma torção!

Introdução
Bases de dados relacionais estão aqui para ficar, independentemente do hype, bem como o advento dos bancos de dados mais recentes, muitas vezes popularmente denominado como 'NoSQL'bases de dados. A razão simples é que esses bancos de dados reforçam a estrutura essencial, as restrições e fornecem uma boa linguagem declarativa para consultar dados, o que nós amamos - SQL! No entanto, a escala sempre foi um problema com bancos de dados relacionais. A maioria das empresas agora no século XXI está carregada de repositórios de dados e repositórios ricos e deseja aproveitar ao máximo seus "Big Data" para obter insights acionáveis. Os bancos de dados relacionais podem ser populares, mas não são dimensionados muito bem, a menos que invistamos em uma estratégia adequada de gerenciamento de Big Data. Isso envolve pensar em possíveis fontes de dados, volume de dados, restrições, esquemas, ETL (extração-transformação-carga), padrões de acesso e consulta e muito mais!

Este artigo abordará alguns excelentes avanços feitos para alavancar o poder dos bancos de dados relacionais, mas "em escala", usando alguns dos componentes mais recentes do Apache Spark - Spark SQL e DataFrames. Mais notavelmente, abordaremos os seguintes tópicos.
1. Motivação e Desafios com o Dimensionamento de Bancos de Dados Relacionais
2. Entendendo o Spark SQL e DataFrames
- Objetivos
- Arquitetura e Recursos
- atuação
3. Um estudo de caso real no Spark SQL com exemplos práticos
Assim, estaremos analisando os principais desafios e motivações para as pessoas que trabalham tanto e investindo tempo na criação de novos componentes no Apache Spark, para que possamos executar o SQL em escala. Também entenderemos a arquitetura principal, as interfaces, os recursos e os benchmarks de desempenho do Spark SQL e DataFrames. Por fim, mas o mais importante, cobriremos um estudo de caso real sobre a análise de ataques de invasão baseados no KDD 99 Cup Data usando o Spark SQL e o DataFrames, aproveitando o Databricks Cloud Platform for Spark!
Motivação e Desafios no Dimensionamento de Bancos de Dados Relacionais para Big Data
Armazenamentos de dados relacionais são fáceis de construir e consultar. Além disso, os usuários e desenvolvedores geralmente preferem escrever consultas declarativas e fáceis de interpretar em uma linguagem legível semelhante à humana, como SQL. No entanto, à medida que os dados começam a aumentar em volume e variedade, a abordagem relacional não se dimensiona bem o suficiente para a criação de aplicativos e sistemas analíticos de big data. A seguir, alguns dos principais desafios.
- Lidar com diferentes tipos e fontes de dados que podem ser estruturados, semi-estruturados e não estruturados.
- Construindo pipelines de ETL de e para várias origens de dados, o que pode levar ao desenvolvimento de muitos códigos personalizados específicos, o que aumenta a dívida técnica ao longo do tempo.
- Capacidade de realizar análises tradicionais baseadas em BI (Business Intelligence) e análises avançadas (aprendizado de máquina, modelagem estatística, etc.), o último dos quais é definitivamente desafiador para executar em sistemas relacionais.
O Big Data Analytics não é algo que acabou de ser inventado ontem! Tivemos sucesso neste domínio com o Hadoop e o paradigma Map-Reduce. Isso era poderoso, mas muitas vezes lento, e também dava aos usuários uma interface de programação processual de baixo nível que exigia que as pessoas escrevessem um monte de código para transformações de dados, mesmo que simples. No entanto, uma vez que o Spark foi lançado, ele realmente revolucionou a forma como a análise de big data era feita com foco na computação na memória, tolerância a falhas, abstrações de alto nível e facilidade de uso.
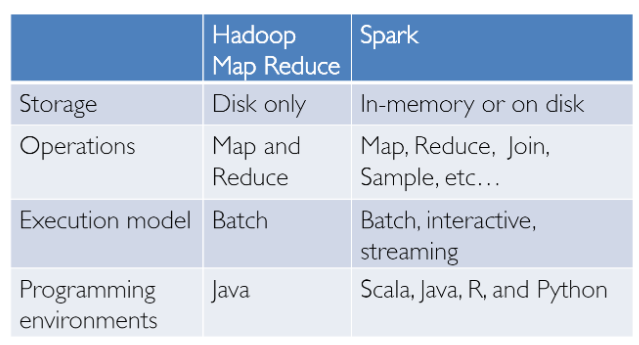
A partir de então, vários frameworks e sistemas como o Hive, Pig e Shark (que evoluíram para o Spark SQL) forneceram interfaces relacionais ricas e mecanismos de consulta declarativa para armazenamentos de Big Data. Permaneceu o desafio de que essas ferramentas fossem relacionais ou baseadas em procedimentos e não poderíamos ter o melhor dos dois mundos.
No entanto, no mundo real, a maioria dos dados e pipelines analíticos pode envolver uma combinação de código relacional e processual. Assim, forçar os usuários a escolher um deles acaba complicando as coisas e aumentando os esforços do usuário no desenvolvimento, construção e manutenção de diferentes aplicativos e sistemas. O Apache Spark SQL se baseia no esforço SQL-on-Spark mencionado anteriormente, chamado Shark. Em vez de forçar os usuários a escolher entre uma API relacional ou uma API processual, o Spark SQL tenta permitir que os usuários misturem os dois sem problemas e realizem consulta, recuperação e análise de dados em escala no Big Data.
Noções básicas sobre o Spark SQL e DataFrames
O Spark SQL essencialmente tenta preencher a lacuna entre os dois modelos que mencionamos anteriormente - os modelos relacionais e procedurais por dois componentes principais.
- O Spark SQL fornece uma API do DataFrame que pode executar operações relacionais em fontes de dados externas e nas coleções distribuídas integradas do Spark - em escala!
- Para oferecer suporte a uma ampla variedade de diversas fontes de dados e algoritmos em big data, o Spark SQL apresenta um novo otimizador extensível chamado Catalyst, que facilita a adição de fontes de dados, regras de otimização e tipos de dados para análise avançada, como aprendizado de máquina.
Essencialmente, o Spark SQL aproveita o poder do Spark para executar cálculos distribuídos e robustos na memória em grande escala no Big Data. O Spark SQL oferece desempenho de SQL avançado e também mantém compatibilidade com todas as estruturas e componentes existentes suportados pelo Apache Hive (uma estrutura popular do Big Data Warehouse), incluindo formatos de dados, funções definidas pelo usuário (UDFs) e o metastore. Além disso, também ajuda a ingerir uma grande variedade de formatos de dados de fontes de Big Data e armazéns de dados de empresas como JSON, Hive, Parquet e assim por diante, e executa uma combinação de operações relacionais e procedurais para análises mais complexas e avançadas.
Objetivos
Vejamos alguns dos fatos interessantes sobre o Spark SQL, seu uso, adoção e objetivos, alguns dos quais vou descaradamente mais uma vez copiar do excelente e original artigo sobre o Processamento de Dados Relacionais no Spark . O Spark SQL foi lançado pela primeira vez em maio de 2014 e talvez seja agora um dos componentes mais desenvolvidos do Spark. O Apache Spark é definitivamente o projeto de código aberto mais ativo para processamento de big data, com centenas de colaboradores. Além de ser apenas um projeto de código aberto, o Spark SQL realmente começou a ver a adoção do setor como um todo! Ele já foi implantado em ambientes de grande escala. Um excelente estudo de caso foi mencionado pelo Facebook, onde eles falam sobre 'Apache Spark @Scale: um caso de uso de produção de 60 TB +' - Aqui, eles estavam fazendo a preparação de dados para o ranking de entidades e seus trabalhos do Hive costumavam levar vários dias e tinham muitos desafios, mas eram capazes de dimensionar e aumentar o desempenho com sucesso usando o Spark. Confira os desafios interessantes que eles enfrentaram nesta jornada!
Outro fato interessante é que 2/3 dos clientes do Databricks Cloud (serviço hospedado rodando o Spark) usam o Spark SQL dentro de outras linguagens de programação. Também mostraremos um estudo de caso prático usando o Spark SQL em Databricks neste artigo. Fique ligado para isso! Os principais objetivos do Spark SQL, conforme definido por seus criadores, são os seguintes.
- Suporta processamento relacional tanto em programas Spark (em RDDs nativos) quanto em fontes de dados externas usando uma API amigável para programadores.
- Forneça alto desempenho usando técnicas estabelecidas de DBMS.
- Suporta facilmente novas fontes de dados, incluindo dados semi-estruturados e bancos de dados externos passíveis de federação de consulta.
- Habilite a extensão com algoritmos avançados de análise, como processamento de gráficos e aprendizado de máquina.
Arquitetura e Recursos
Vamos agora dar uma olhada nos principais recursos e arquitetura em torno do Spark SQL e DataFrames. Alguns conceitos-chave a ter em mente aqui seriam em torno do ecossistema Spark, que tem evoluído constantemente ao longo do tempo.
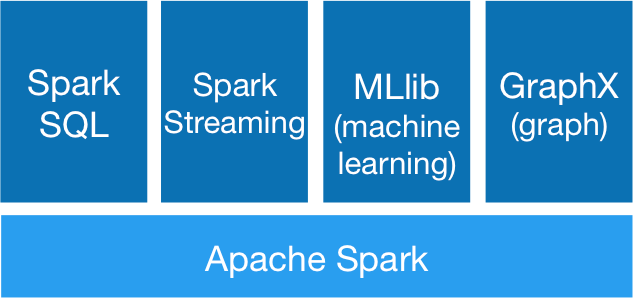
RDDs ou “Conjuntos de Dados Distribuídos Resilientes” é talvez o maior contribuinte por trás de todas as histórias de sucesso da Spark. É basicamente uma estrutura de dados ou melhor, uma abstração de memória distribuída para ser mais precisa, que permite aos programadores realizar cálculos na memória em grandes clusters distribuídos, mantendo aspectos como a tolerância a falhas. Você também pode paralelizar muitos cálculos, transformações e rastrear toda a linhagem de transformações, o que pode ajudar na recomputação eficiente de dados perdidos. Os entusiastas do Spark leem o excelente artigo sobre RDDs, 'Conjuntos de Dados Distribuídos Resilientes: Uma Abstração Tolerante a Falhas para Computação em Cluster In-Memory' . Além disso, o Spark trabalha com o conceito de motoristas e trabalhadores, conforme ilustrado na figura a seguir.
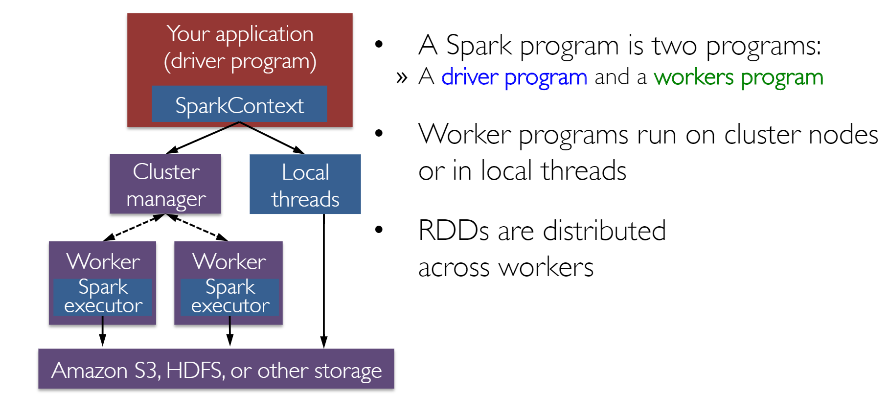
Normalmente, você pode criar um RDD lendo dados de arquivos, bancos de dados, paralelizando coleções existentes ou até mesmo transformações. Normalmente transformações são operações que podem ser usadas para transformar os dados em diferentes aspectos e dimensões, dependendo da maneira como queremos organizar e processar os dados. Eles também são avaliados com preguiça, o que significa que, mesmo se você definir uma transformação, os resultados não serão calculados até você aplicar uma açãoque normalmente requer que um resultado seja retornado ao programa do driver (e calculou todas as transformações aplicadas!).
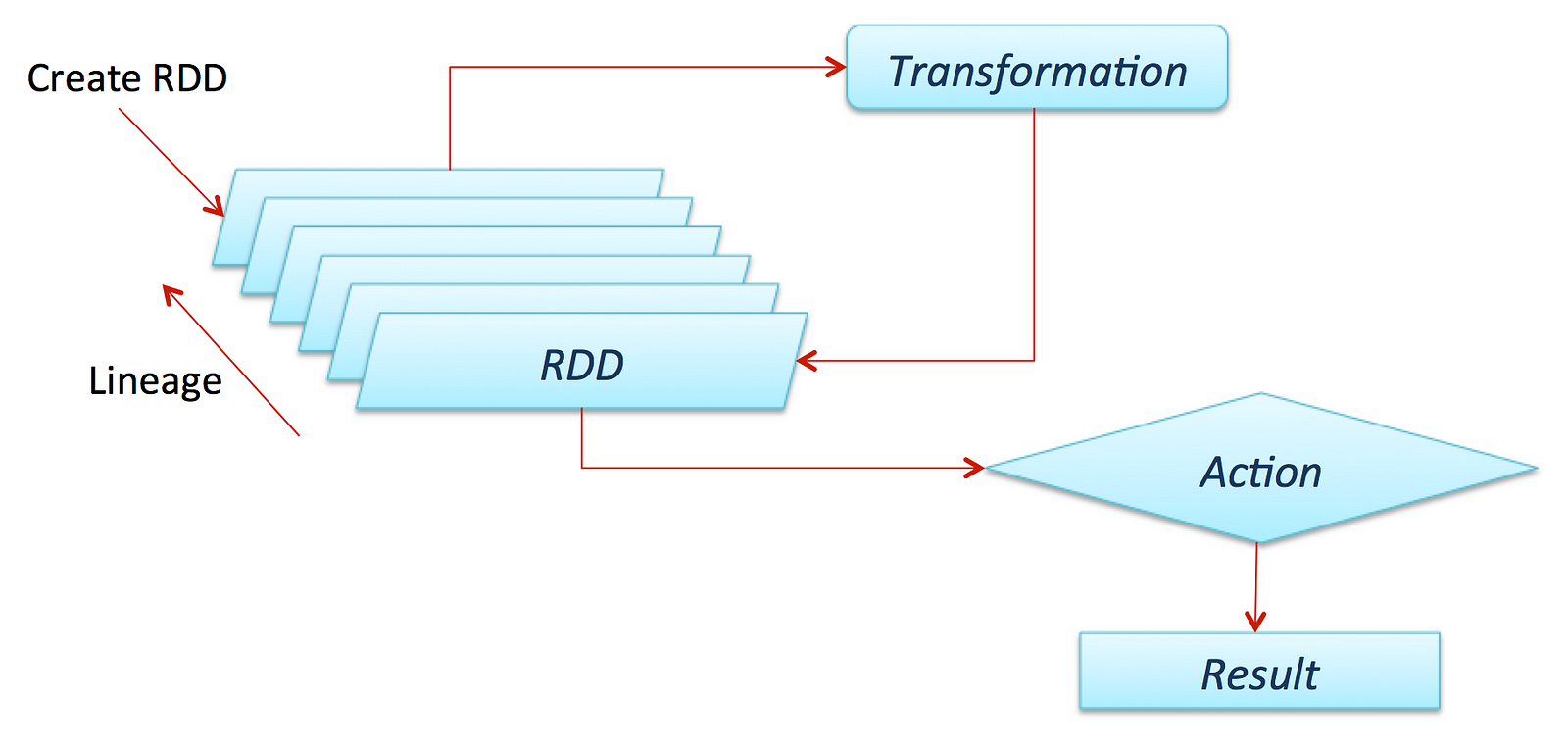
Grite para o colega cientista de dados e amigo Favio Vázquez e seu excelente artigo sobre Aprendizado Profundo com o Apache Spark, do qual obtive algumas excelentes ideias e conteúdo, incluindo a figura anterior. Confira!
Agora que sabemos sobre a arquitetura geral de como o Spark funciona, vamos dar uma olhada no Spark SQL. Normalmente, o Spark SQL é executado como uma biblioteca no topo do Spark, como vimos na figura que abrange o ecossistema Spark. A figura a seguir dá uma olhada mais detalhada na arquitetura e interfaces típicas do Spark SQL.
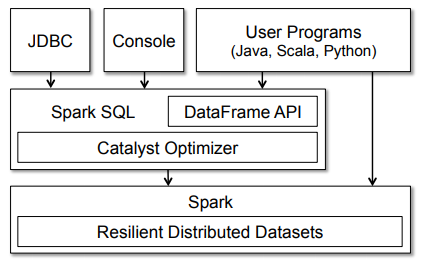
A figura nos mostra claramente as várias interfaces SQL, que podem ser acessadas através de JDBC / ODBC ou através de um console de linha de comando, bem como a API DataFrame integrada nas linguagens de programação suportadas do Spark (usaremos o Python!). A API DataFrame é muito poderosa e permite aos usuários finalmente misturar código processual e relacional! Funções avançadas como UDFs (funções definidas pelo usuário) também podem ser expostas no SQL, que podem ser usadas por ferramentas de BI.
Os Spark DataFrames são muito interessantes e nos ajudam a aproveitar o poder do Spark SQL e combinar seus paradigmas processuais conforme necessário. Um Spark DataFrame é basicamente uma coleção distribuída de linhas (tipos de linha) com o mesmo esquema. É basicamente um conjunto de dados do Spark organizado em colunas nomeadas. Um ponto a ser observado aqui é que Datasets , são uma extensão da API DataFrame que fornece uma interface de programação orientada a objeto, segura para o tipo. Portanto, eles estão disponíveis apenas em Java e Scala e, portanto, estaremos nos concentrando em DataFrames.
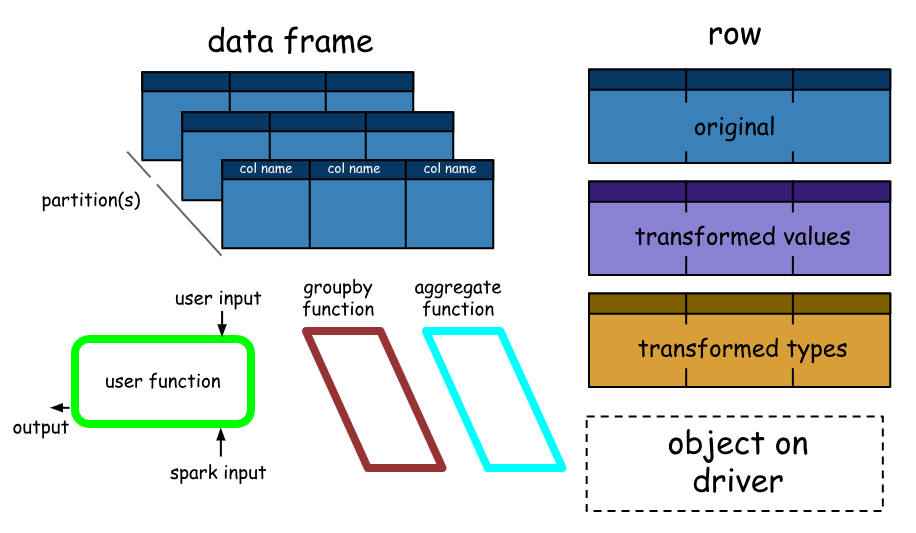
Um DataFrame é equivalente a uma tabela em um banco de dados relacional (mas com mais otimizações sob o capô) e também pode ser manipulado de maneira semelhante às coleções distribuídas “nativas” no Spark (RDDs). Os Spark DataFrames têm algumas propriedades interessantes, algumas das quais são mencionadas abaixo.
- Ao contrário dos RDDs, os DataFrames geralmente acompanham seu esquema e suportam várias operações relacionais que levam a uma execução mais otimizada.
- Os DataFrames podem ser construídos a partir de tabelas, da mesma forma que as tabelas Hive existentes em sua infraestrutura Big Data ou até mesmo de RDDs existentes.
- Os DataFrames podem ser manipulados com consultas SQL diretas e também usando o DataFrame DSL (linguagem específica do domínio), onde podemos usar vários operadores relacionais e transformadores, como where e groupBy
- Além disso, cada DataFrame também pode ser visualizado como um RDD de objetos Row, permitindo que os usuários chamem APIs de falha de procedimento, como mapear
- Finalmente, um dado, mas um ponto para lembrar sempre, ao contrário das tradicionais APIs de dados (pandas), os Spark DataFrames são preguiçosos, pois cada objeto DataFrame representa um plano lógico para computar um conjunto de dados, mas nenhuma execução ocorre até que o usuário chame um especial “ operação de saída ”como salvar.
Isso deve fornecer perspectivas suficientes sobre o Spark SQL, DataFrames, recursos essenciais, conceitos, arquitetura e interfaces. Vamos encerrar esta seção dando uma olhada nos benchmarks de desempenho.
atuação
Liberar um novo recurso sem as otimizações certas pode ser fatal, e o pessoal que criou o Spark fez vários testes de desempenho e benchmarking! Vamos dar uma olhada em alguns resultados interessantes. A primeira figura mostrando alguns resultados é mostrada abaixo.
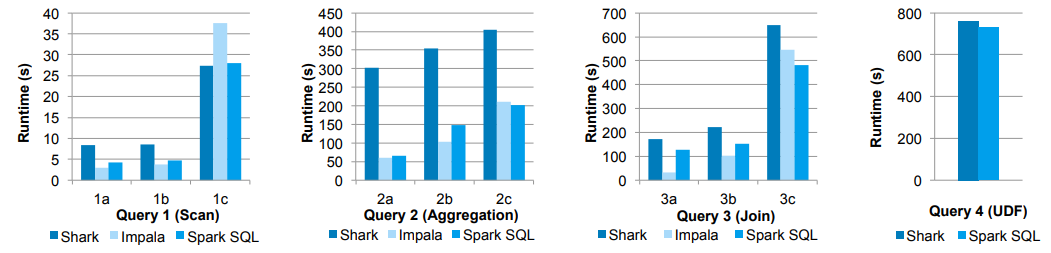
Nesses experimentos, eles compararam o desempenho do Spark SQL com o Shark e o Impala usando o benchmark de big data AMPLab, que usa uma carga de trabalho de análise da Web desenvolvida por Pavlo et al. O benchmark contém quatro tipos de consultas com diferentes parâmetros que executam varreduras, agregação, junções e um trabalho MapReduce baseado em UDF. O conjunto de dados foi de 110 GB de dados após a compactação usando o formato colunar Parquet. Vemos que em todas as consultas, o Spark SQL é substancialmente mais rápido que o Shark e geralmente é competitivo com o Impala. O otimizador do Catalyst é responsável por isso, o que reduz a sobrecarga da CPU (abordaremos isso brevemente). Esse recurso torna o Spark SQL competitivo com o mecanismo Impala baseado em C ++ e LLVM em muitas dessas consultas. A maior lacuna da Impala está em
query 3a onde o Impala escolhe um plano de junção melhor, porque a seletividade das consultas torna uma das tabelas muito pequena.
Os gráficos a seguir mostram mais alguns benchmarks de desempenho para DataFrames e APIs Spark e Spark + SQL comuns.

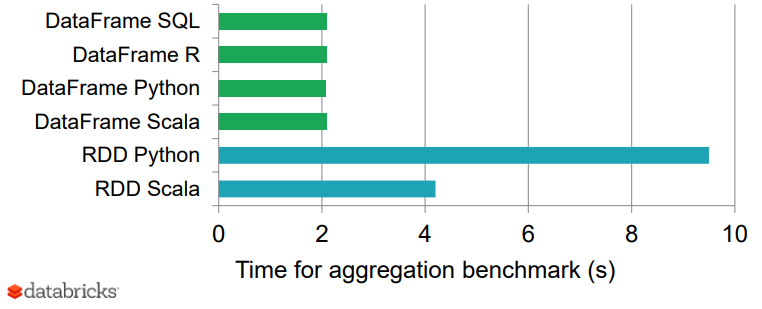
Finalmente, o gráfico a seguir mostra um bom resultado de benchmark de DataFrames vs. RDDs em diferentes idiomas, o que dá uma perspectiva interessante de como os DataFrames otimizados podem ser!
Segredo para o desempenho - O catalisador otimizador
Por que o Spark SQL é tão rápido e otimizado? A razão é, por causa de um novo otimizador extensível, o Catalyst, baseado em construções de programação funcional no Scala. Apesar de não entrarmos em detalhes muito extensos sobre o Catalyst aqui, vale a pena mencionar, já que ajuda a otimizar as operações e consultas do DataFrame.
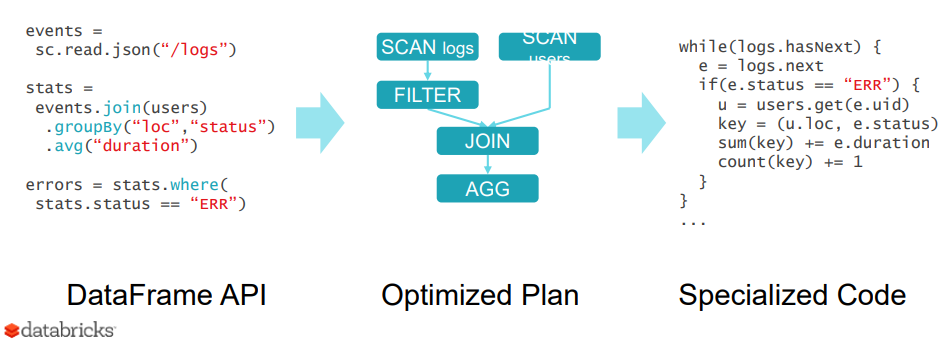
O design extensível do Catalyst tem dois propósitos.
- Facilitando a adição de novas técnicas e recursos de otimização ao Spark SQL, especialmente para lidar com diversos problemas relacionados a 'Big Data', dados semiestruturados e análises avançadas.
- Facilidade de poder estender o otimizador - por exemplo, adicionando regras específicas da fonte de dados que podem enviar filtragem ou agregação em sistemas de armazenamento externo ou oferecer suporte a novos tipos de dados.
O Catalyst suporta otimização baseada em regras e baseada em custo. Embora os otimizadores extensíveis tenham sido propostos no passado, eles normalmente exigiam uma linguagem específica de domínio complexa para especificar regras. Geralmente, isso leva a uma curva de aprendizado significativa e a um ônus de manutenção. Em contraste, o Catalyst usa os recursos padrão da linguagem de programação Scala, como a correspondência de padrões, para permitir que os desenvolvedores usem a linguagem de programação completa e, ao mesmo tempo, tornar as regras fáceis de especificar.
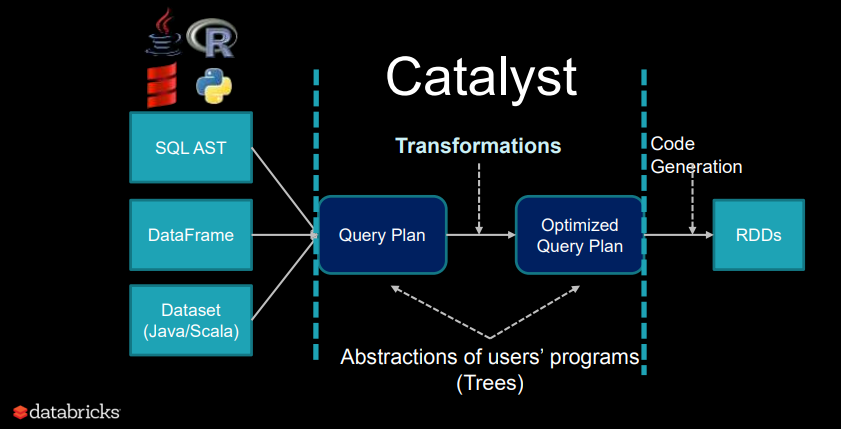
Em sua essência, o Catalyst contém uma biblioteca geral para representar árvores e aplicar regras para manipulá-las. No topo dessa estrutura, ele possui bibliotecas específicas para o processamento de consultas relacionais (por exemplo, expressões, planos de consulta lógica) e vários conjuntos de regras que lidam com diferentes fases de execução de consultas: análise, otimização lógica, planejamento físico e geração de código para compilar. partes de consultas para bytecode Java. Interessado em saber mais detalhes sobre o Catalyst e fazer um mergulho profundo? Você pode conferir um excelente artigo da Databricks!
Estudo de caso prático com o Spark SQL
Agora faremos um tutorial simples com base em um conjunto de dados do mundo real para ver como usar o Spark SQL. Nós estaremos usando Spark DataFrames, mas o foco será mais em usar SQL. Eu estarei cobrindo uma discussão detalhada sobre Spark DataFrames e operações comuns em um artigo separado. Eu adoro usar serviços de nuvem para meu aprendizado de máquina, aprendizado profundo e até mesmo necessidades de Big Data Analytics. Em vez de configurar seu próprio cluster do Spark, use um dos melhores da nuvem! Nós estaremos usando a Plataforma Databricks para as nossas necessidades Spark! A Databricks é uma empresa fundada pelos criadores do Apache Spark, que tem como objetivo ajudar clientes com processamento de big data baseado em nuvem usando o Spark.

A maneira mais simples (e gratuita) é ir para a página Try Databricks e se inscrever para uma conta usando a edição da comunidade onde você obtém um cluster baseado em nuvem, que é um cluster de nó único com 6 GB e cadernos ilimitados, não ruim para uma versão gratuita! Eu definitivamente recomendo usar a Plataforma Databricks se você tiver sérias necessidades para analisar Big Data!
Vamos começar com o nosso estudo de caso agora, sinta-se à vontade para criar um novo bloco de notas a partir de sua tela inicial no Databricks ou em seu próprio cluster do Spark, conforme descrito no instantâneo a seguir.
Você também pode importar meu bloco de anotações contendo todo o tutorial, mas executar todas as células e brincar com elas e explorar em vez de apenas lê-las. Não sabe como usar o Spark em Databricks? Siga este breve mas útil tutorial e comece hoje mesmo!
Este tutorial irá familiarizá-lo com os recursos essenciais do Spark para lidar com dados estruturados geralmente obtidos de bancos de dados ou arquivos simples. Vamos explorar formas típicas de consultar e agregar dados relacionais, aproveitando conceitos de DataFrames e SQL usando o Spark. Vamos trabalhar em um conjunto de dados interessante da KDD Cup 1999e tente consultar os dados usando abstrações de alto nível, como o dataframe, que já foi um sucesso em ferramentas populares de análise de dados, como R e Python. Também veremos como é fácil criar consultas de dados usando a linguagem SQL, que você aprendeu e recuperar informações detalhadas de nossos dados. Isso também acontece em escala sem que tenhamos que fazer muito mais, já que o Spark distribui essas estruturas de dados de maneira eficiente no back-end, o que torna nossas consultas escaláveis e tão eficientes quanto possível. Começamos carregando algumas dependências básicas.
import pandas como pd
import matplotlib.pyplot como plt
plt.style.use ('fivethirtyeight')
Recuperação de dados
Usaremos os dados da KDD Cup 1999 , que é o conjunto de dados usado para a Terceira Competição Internacional de Ferramentas de Descoberta de Conhecimento e Mineração de Dados, realizada em conjunto com a KDD-99 A Quinta Conferência Internacional sobre Descoberta de Conhecimento e Mineração de Dados. A tarefa da competição era construir um detector de intrusão de rede, um modelo preditivo capaz de distinguir entre conexões ruins , chamadas intrusões ou ataques, e boas conexões normais . Este banco de dados contém um conjunto padrão de dados a serem auditados, que inclui uma ampla variedade de intrusões simuladas em um ambiente de rede militar.
Nós estaremos usando o conjunto de dados reduzido
kddcup.data_10_percent.gzcontendo quase meio milhão de interações nework, já que estaríamos baixando este arquivo Gzip da web localmente, e então trabalharíamos no mesmo. Se você tiver uma conexão de internet estável e boa, sinta-se à vontade para baixar e trabalhar com o conjunto de dados completo disponível como kddcup.data.gz.Trabalhando com dados da web
Lidar com conjuntos de dados recuperados da Web pode ser um pouco complicado em Databricks. Felizmente, temos alguns pacotes de utilitários excelentes, como os
dbutilsque ajudam a tornar nosso trabalho mais fácil. Vamos dar uma olhada rápida em algumas funções essenciais para este módulo.dbutils.help ()
Este módulo fornece vários utilitários para os usuários interagirem com o restante dos Databricks.
fs: DbfsUtils -> Manipula o sistema de arquivos Databricks (DBFS) do console meta: MetaUtils -> Métodos para conectar ao compilador (EXPERIMENTAL) notebook: NotebookUtils -> Utilitários para o fluxo de controle de um bloco de anotações (EXPERIMENTAL) preview: Preview -> Utilitários sob segredos da categoria de visualização : SecretUtils -> Fornece utilitários para alavancar segredos dentro de widgets de notebooks : WidgetsUtils -> Métodos para criar e obter valor vinculado de widgets de entrada dentro de blocos de anotações
Recuperar e armazenar dados no Databricks
Vamos agora alavancar a
urllibbiblioteca python para extrair os dados do KDD Cup 99 de seu repositório web, armazená-los em um local temporário e, em seguida, movê-los para o sistema de arquivos Databricks, que pode permitir acesso fácil a esses dados para análise
Nota: Se você pular esta etapa e baixar os dados diretamente, poderá acabar recebendo um InvalidInputException: Input path does not existerro

Construindo o conjunto de dados do KDD
Agora que temos nossos dados armazenados no sistema de arquivos do Databricks, vamos carregar nossos dados do disco para a estrutura de dados abstratas tradicional do Spark, o RDD (Resilient Distributed Dataset)

Você também pode verificar o tipo de estrutura de dados de nossos dados (RDD) usando o seguinte código.
tipo (raw_rdd)

Criando um DataFrame Spark em nossos dados
Um Spark DataFrame é uma estrutura de dados interessante que representa uma coleta distribuída de dados. Normalmente, o ponto de entrada em todas as funcionalidades SQL no Spark é a
SQLContextclasse. Para criar uma instância básica desta chamada, tudo o que precisamos é de uma SparkContextreferência. Em Databricks, esse objeto de contexto global está disponível scpara esse propósito.
Dividindo os dados CSV
Cada entrada em nosso RDD é uma linha separada por vírgula de dados que precisamos primeiro dividir antes de podermos analisar e construir nosso dataframe.

Verificar o número total de recursos (colunas)
Podemos usar o código a seguir para verificar o número total de colunas em potencial no nosso conjunto de dados.
len (csv_rdd.take (1) [0])
Fora [57]: 42
Compreensão e análise de dados
Os dados do KDD 99 Cup consistem em diferentes atributos capturados dos dados de conexão. A lista completa de atributos nos dados pode ser obtida aqui e mais detalhes referentes à descrição de cada atributo \ coluna podem ser encontrados aqui . Vamos usar apenas algumas colunas específicas do conjunto de dados, cujos detalhes são especificados da seguinte forma.
Nós iremos extrair as seguintes colunas com base em suas posições em cada datapoint (linha) e construir um novo RDD da seguinte maneira.

Construindo o DataFrame
Agora que nossos dados são analisados e formatados, vamos construir nosso DataFrame!
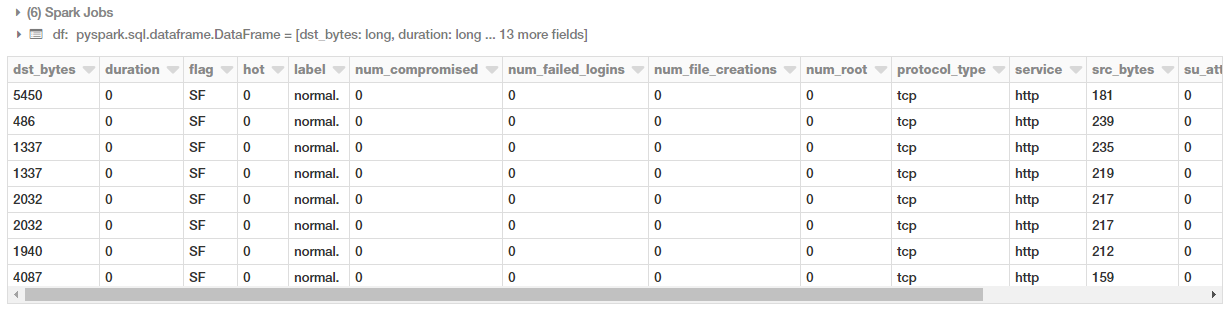
Você também pode verificar o esquema do nosso dataframe usando o seguinte código.
df.printSchema ()

Construindo uma mesa temporária
Podemos aproveitar a
registerTempTable()função para construir uma tabela temporária para executar comandos SQL em nosso DataFrame em escala! Um ponto a lembrar é que a vida útil dessa tabela temporária está vinculada à sessão. Ele cria uma tabela na memória com escopo para o cluster no qual foi criada. Os dados são armazenados usando o formato colunar em memória altamente otimizado do Hive.
Você também pode verificar
saveAsTable()qual cria uma tabela física permanente armazenada no S3 usando o formato Parquet. Esta tabela é acessível a todos os clusters. Os metadados da tabela, incluindo a localização do (s) arquivo (s), são armazenados no metastore Hive.ajuda (df.registerTempTable)

df.registerTempTable ("connections")
Executando o SQL na escala
Vejamos alguns exemplos de como podemos executar consultas SQL em nossa tabela com base em nosso dataframe. Começaremos com algumas consultas simples e, em seguida, veremos agregações, filtros, classificação, subconsultas e pivôs neste tutorial.
Conexões baseadas no tipo de protocolo
Vamos ver como podemos obter o número total de conexões com base no tipo de protocolo de conectividade. Primeiro, obteremos essas informações usando a sintaxe DSL DataFrame normal para realizar agregações.

Podemos também usar o SQL para realizar a mesma agregação? Sim, podemos aproveitar a tabela que criamos anteriormente para isso!

Você pode ver claramente que obtém os mesmos resultados e não precisa se preocupar com sua infraestrutura de segundo plano ou como o código é executado. Apenas escreva SQL simples!
Conexões baseadas em assinaturas boas ou ruins (tipos de ataque)
Agora, executaremos uma agregação simples para verificar o número total de conexões com base nos tipos bom (normal) ou ruim (ataques de intrusão).

Temos muitos tipos de ataques diferentes. Podemos visualizar isso na forma de um gráfico de barras. A maneira mais simples é usar as excelentes opções de interface no próprio notebook do Databricks!

Isso nos dá o seguinte gráfico de barras bonito! Que você pode personalizar ainda mais clicando em
Plot Optionsconforme necessário.
Outra maneira é escrever o código para fazer isso. Você pode extrair os dados agregados como um DataFrame pandas e, em seguida, traçar como um gráfico de barras regular.
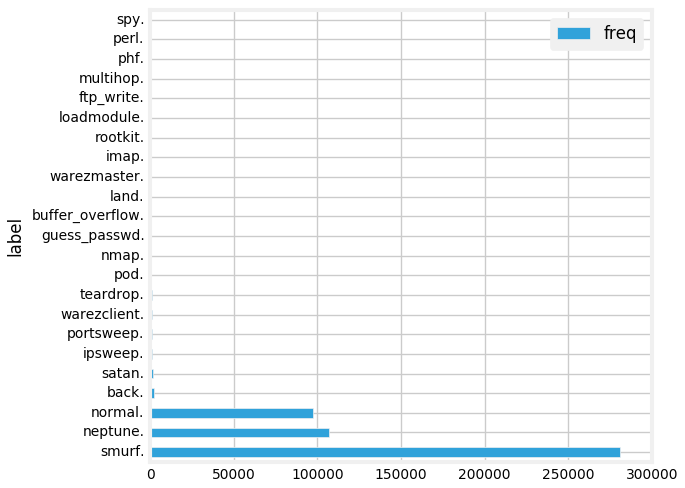
Conexões baseadas em protocolos e ataques
Vamos ver quais protocolos são mais vulneráveis a ataques agora baseados na seguinte consulta SQL.

Bem, parece que conexões ICMP seguidas por conexões TCP tiveram o máximo de ataques!
Estatísticas de conexão baseadas em protocolos e ataques
Vamos dar uma olhada em algumas medidas estatísticas relativas a esses protocolos e ataques para nossas solicitações de conexão.
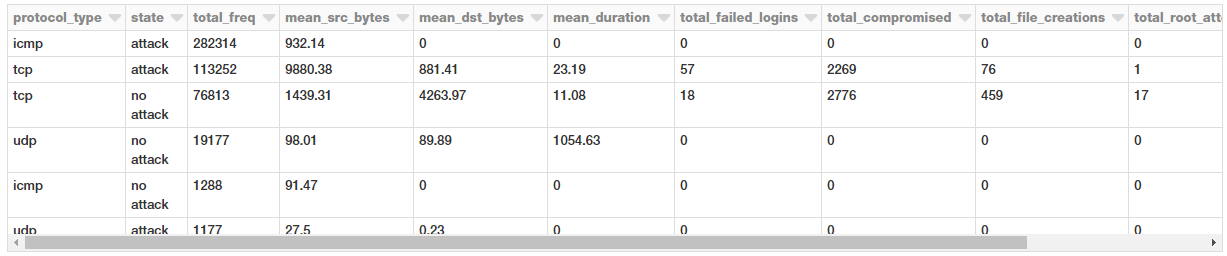
Parece que a quantidade média de dados sendo transmitidos em solicitações TCP é muito maior, o que não é surpreendente. Curiosamente, os ataques têm uma carga média muito maior de dados transmitidos da origem para o destino.
Filtrando as estatísticas de conexão com base no protocolo TCP por serviço e tipo de ataque
Vamos dar uma olhada mais de perto nos ataques TCP, já que temos dados e estatísticas mais relevantes para o mesmo. Vamos agora agregar diferentes tipos de ataques TCP com base no serviço, tipo de ataque e observar diferentes métricas.
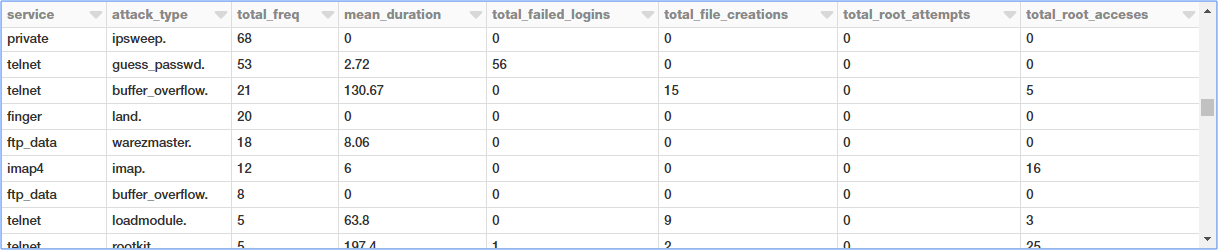
Existem muitos tipos de ataque e a saída anterior mostra uma seção específica do mesmo.
Filtrando as estatísticas de conexão com base no protocolo TCP por serviço e tipo de ataque
Agora, filtraremos alguns desses tipos de ataque, impondo algumas restrições com base na duração, nas criações de arquivos, nos acessos raiz em nossa consulta.

Subconsultas para filtrar tipos de ataque TCP com base no serviço
Vamos tentar obter todos os ataques TCP com base no serviço e no tipo de ataque, de forma que a duração média geral desses ataques seja maior que zero (
> 0). Para isso, podemos fazer uma consulta interna com todas as estatísticas de agregação e, em seguida, extrair as consultas relevantes e aplicar um filtro de duração média na consulta externa, conforme mostrado abaixo.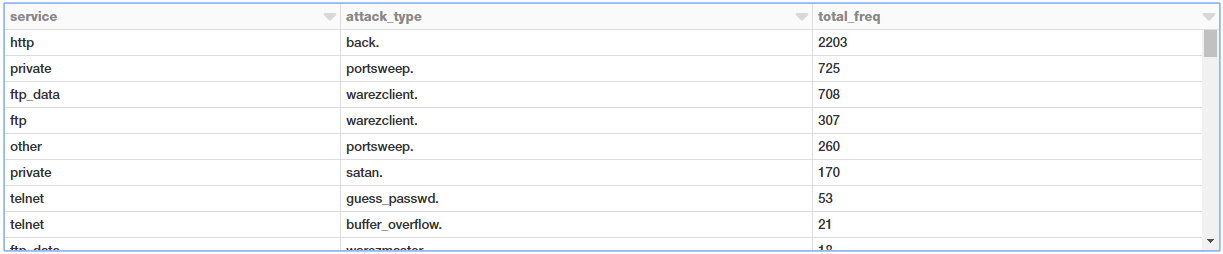
Isso é legal! Agora, uma maneira interessante de também visualizar esses dados é usar uma tabela dinâmica em que um atributo representa linhas e outro representa colunas. Vamos ver se podemos aproveitar o Spark DataFrames para fazer isso!
Construindo uma tabela dinâmica a partir de dados agregados
Aqui, vamos nos basear no objeto DataFrame anterior que obtivemos onde agregamos ataques com base em tipo e serviço. Para isso, podemos aproveitar o poder do Spark DataFrames e do DataFrame DSL.

Nós obtemos uma boa tabela dinâmica mostrando todas as ocorrências baseadas no serviço e no tipo de ataque!
Próximos passos
Gostaria de incentivá-lo a sair e jogar com o Spark SQL e DataFrames, você pode até importar o meu notebook e jogar com você mesmo em sua própria conta.
Sinta-se livre para se referir ao meu repositório GitHub também para todo o código e cadernos usados neste artigo. O que nós não cobrimos aqui inclui o seguinte.
- Joins
- Funções da janela
- Operações detalhadas e Transformações de DataFrames do Spark
Há uma abundância de artigos / tutoriais disponíveis on-line, então eu recomendo que você os veja. Alguns recursos úteis para você verificar incluem o guia completo do Spark SQL do Databricks .



Unuereal_yu2001 Brenda Alvarez link
ResponderExcluirtisodospgras