Interpretando os coeficientes de regressão linear
Interpretando os coeficientes de regressão linear

Aprenda a interpretar corretamente os resultados da regressão linear - incluindo casos com transformações de variáveis
Atualmente, há uma infinidade de algoritmos de aprendizado de máquina que podemos tentar encontrar o melhor ajuste para nosso problema específico. Alguns algoritmos têm uma interpretação clara, outros funcionam como uma caixa preta e podemos usar abordagens como LIME ou SHAP para derivar algumas interpretações.
Neste artigo, gostaria de focar na interpretação dos coeficientes do modelo de regressão mais básico, a regressão linear , incluindo as situações em que variáveis dependentes / independentes foram transformadas (neste caso, estou falando sobre transformação de log).
1. modelo de nível de nível
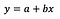

Suponho que o leitor esteja familiarizado com a regressão linear (se não houver muitos bons artigos e posts médios), portanto, focarei apenas na interpretação dos coeficientes.
A fórmula básica para a regressão linear pode ser vista acima (eu omiti os resíduos de propósito, para manter as coisas simples e objetivas). Na fórmula, Y indica a variável dependente e x é a variável independente. Para simplificar, vamos supor que seja uma regressão univariada, mas os princípios obviamente também são válidos para o caso multivariado.
Para colocá-lo em perspectiva, digamos que depois de ajustar o modelo que recebemos:
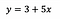

Interceptação (a)
Vou dividir a interpretação da interceptação em dois casos:
- x é contínuo e centralizado (subtraindo a média de x de cada observação, a média de x transformado se torna 0) - média y é 3 quando x é igual à média da amostra
- x é contínuo, mas não centrado - a média y é 3 quando x = 0
- x é categórico - a média y é 3 quando x = 0 (desta vez indicando uma categoria, mais sobre isso abaixo)
Coeficiente (b)
- x é uma variável contínua
Interpretação: um aumento unitário em x resulta em um aumento médio de y em 5 unidades, todas as outras variáveis mantidas constantes.
- x é uma variável categórica
Isso requer um pouco mais de explicação. Digamos que x descreva o gênero e possa assumir valores ('masculino', 'feminino'). Agora vamos convertê-lo em uma variável dummy que recebe valores 0 para homens e 1 para mulheres.
Interpretação: y médio é maior em 5 unidades para mulheres do que para homens, todas as outras variáveis mantidas constantes.
2. modelo em nível de log
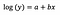

Normalmente, usamos a transformação de log para extrair dados externos de uma distribuição inclinada positivamente para mais perto da maior parte dos dados, a fim de tornar a variável normalmente distribuída. No caso de regressão linear, um benefício adicional do uso da transformação de log é a interpretabilidade.

Como antes, digamos que a fórmula abaixo apresente os coeficientes do modelo ajustado.
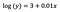

Interceptação (a)
A interpretação é semelhante à do caso da baunilha (nível de nível), no entanto, precisamos usar o expoente da interceptação para interpretação exp (3) = 20.09. A diferença é que esse valor representa a média geométrica de y (em oposição à média aritmética no caso do modelo de nível de nível).
Coeficiente (b)
Os princípios são novamente semelhantes ao modelo de nível de nível quando se trata de interpretar variáveis categóricas / numéricas. Analogamente à interceptação, precisamos pegar o expoente do coeficiente: exp ( b ) = exp (0,01) = 1,01. Isso significa que um aumento unitário em x causa um aumento de 1% na média (geométrica) y , todas as outras variáveis mantidas constantes.
Duas coisas que vale a pena mencionar aqui:
- Existe uma regra de ouro quando se trata de interpretar coeficientes desse modelo. Se abs (b) <0,15, é bastante seguro dizer que, quando b = 0,1, observaremos um aumento de 10% em y para uma mudança de unidade em x . Para coeficientes com maior valor absoluto, recomenda-se calcular o expoente.
- Ao lidar com variáveis no intervalo [0, 1] (como uma porcentagem), é mais conveniente para a interpretação multiplicar primeiro a variável por 100 e depois ajustar o modelo. Dessa forma, a interpretação é mais intuitiva, pois aumentamos a variável em 1 ponto percentual em vez de 100 pontos percentuais (de 0 a 1 imediatamente).
3. modelo de log de nível
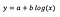

Vamos supor que depois de ajustar o modelo que recebemos:


A interpretação da interceptação é a mesma que no caso do modelo de nível de nível.
Para o coeficiente b - um aumento de 1% em x resulta em um aumento aproximado da média y em b / 100 (0,05 neste caso), todas as outras variáveis mantidas constantes . Para obter a quantidade exata, precisaríamos usar b × log (1,01), que neste caso fornece 0,0498.
4. modelo de log-log
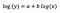

Vamos supor que depois de ajustar o modelo que recebemos:
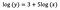

Mais uma vez, concentro-me na interpretação de b. Um aumento de x em 1% resulta em um aumento de 5% na média (geométrica) y , todas as outras variáveis mantidas constantes. Para obter a quantidade exata, precisamos tomar
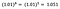

que é ~ 5,1%.
Conclusões
Espero que este artigo tenha fornecido uma visão geral de como interpretar coeficientes de regressão linear, incluindo os casos em que algumas das variáveis foram transformadas em log. Como sempre, qualquer feedback construtivo é bem-vindo. Você pode entrar em contato comigo no Twitter ou nos comentários.



Comentários
Postar um comentário